- Published on
Kubernetes Introduction
- Authors
I've been using Kubernetes for more than a year since I started working as a backend engineer for Atados. During this time, I've learned A LOT about how Kubernetes works, how to deploy and manage applications, and how useful this technology is. But, besides learning a lot, my gut feeling always told me I should understand the Kubernetes ecosystem in more depth.
That's why I'm starting this series of posts focused on Kubernetes. I will take a step back and re-learn everything from the very beginning. What is a cluster, deployment, pod, replica, ingress, service, etc? How to scale vertically and horizontally? How do you manage deployments with Helm? How do you set up a CD pipeline in a Kubernetes environment?
Series Overview
To structure my learning, I've decided to use the Kubernetes roadmap from roadmap.sh because it seems to cover core concepts and in good order.
To get started, this post will cover the following topics:
- Overview of Kubernetes
- Why Kubernetes?
- Key Concepts and Terminologies
- Kubernetes Alternatives
Overview of Kubernetes
From the official documentation, Kubernetes is:
a portable, extensible, open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. It has a large, rapidly growing ecosystem.
Its creation is a result of many years of deployment strategy evolutions, starting with physical servers, then virtual machines (VMs), and finally, containers.
In summary, what Kubernetes does is manage containers. Not only that but it is flexible in terms of the environment the containers are running (physical, virtual, cloud, or hybrid).
The k8s ecosystem is particularly useful for applications that have a microservices architecture, which has become more popular with the rise of the containerization of monolithic applications. In fact, most of the k8s development was a result of the high demand for a tool to orchestrate containers.
The main tools k8s offer are:
- High availability
- Scalability
- Disaster recovery: backup and restore
- Observability
Basic Architecture
When k8s is deployed, a cluster is created. The cluster consists of a control plane and worker nodes (a k8s cluster will have at least one worker node).
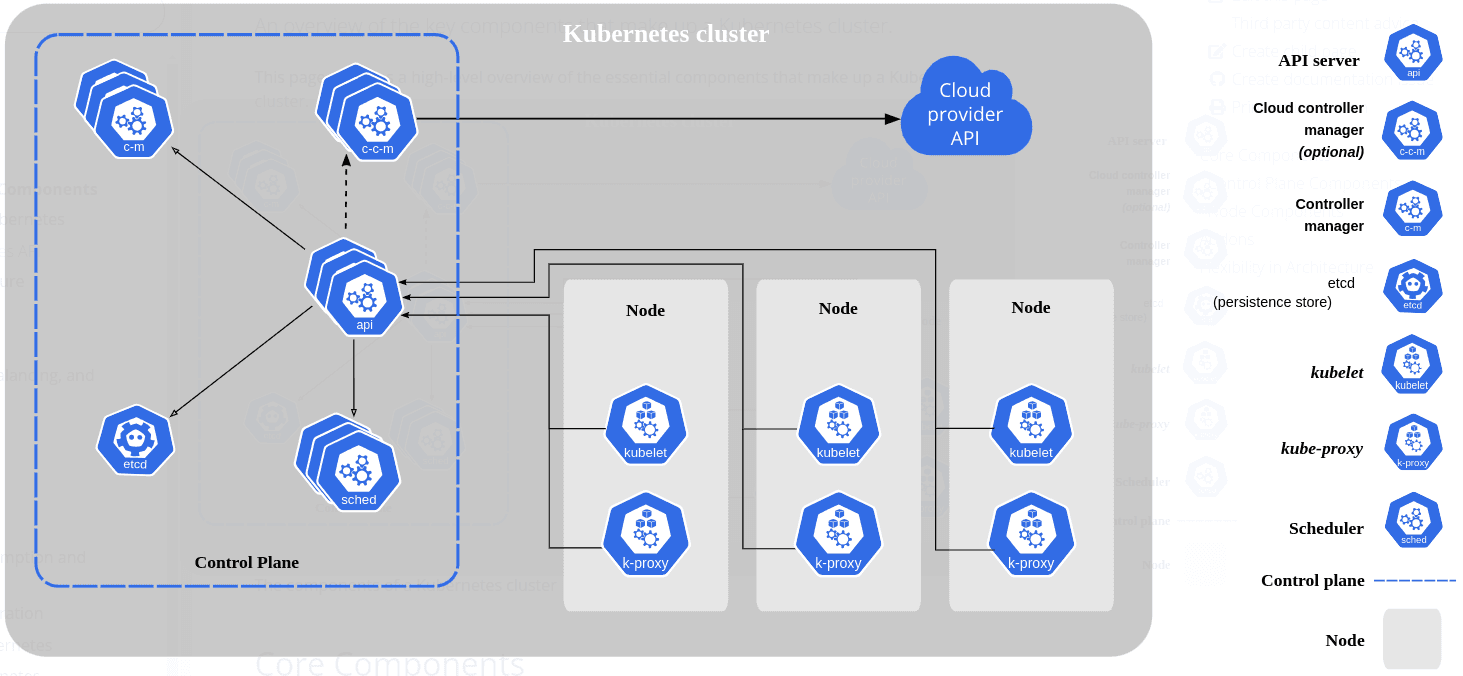
The control plane has the following components:
- API Server: It is the entry point to the cluster. The API server process is used by a UI, script, or CLI.
- Controller Manager: Keeps track of what is happening in the cluster.
- Scheduler: process responsible for deciding what worker node the containers should run.
- Etcd: It is a key-value storage that holds configuration and cluster state.
The worker nodes, on the other hand, have:
- Kubelet: Process responsible for communication with cluster and running applications.
- Kube-proxy: Maintain network rules for the node which may allow communication within the cluster or outside it.
- Containers: The containers deployed for the applications in the cluster.
Besides that, there is also a virtual network that bonds together the control plane and worker nodes and makes the cluster a powerful unified machine.
The control plane is the most important thing in a k8s, even though it requires way fewer resources since the application containers run on the worker nodes.
Why Kubernetes?
Kubernetes is a powerful tool for managing containers, but why should we use it?
Looking at the official documentation again:
Kubernetes provides you with a framework to run distributed systems resiliently. It takes care of scaling and failover for your application, provides deployment patterns, and more.
There are several reasons to use k8s, some of them are:
- It can expose containers via DNS names or unique IP addresses, allowing it to distribute traffic efficiently to maintain deployment stability, especially during high-traffic periods.
- It supports storage orchestration, enabling users to automatically mount various storage systems like local storage or public cloud providers.
- Kubernetes offers automated rollouts and rollbacks, allowing users to define the desired state of containers and smoothly transition to it by creating, removing, or adapting containers as needed.
- Resource usage optimization is achieved through automatic bin packing, fitting containers onto nodes based on their CPU and memory requirements for efficient resource utilization.
- K8s provides self-healing features by restarting or replacing containers that fail and ensuring containers meet user-defined health checks before they are exposed to clients.
- For sensitive data like passwords or API keys, it offers a way to store them without exposing their values in configuration files, allowing for seamless updates without rebuilding container images.
- It also manages batch and CI workloads and enables horizontal scaling of applications either manually or automatically based on CPU usage.
Key Concepts and Terminologies
Namespaces
In Kubernetes, namespaces provide a mechanism for isolating groups of resources within a single cluster. Names of resources need to be unique within a namespace, but not across namespaces. Namespace-based scoping is applicable only for namespaced objects (e.g. Deployments, Services, etc.) and not for cluster-wide objects (e.g. StorageClass, Nodes, PersistentVolumes, etc.).
The important takeaways for k8s namespaces are:
- They are useful for dividing resources among several users or isolate environments (production, staging, development, etc)
- When a Service is created, a DNS entry is created too with the namespace associated with it:
<service-name>.<namespace-name>.svc.cluster.local. This is useful for using the same configuration across environments. - Not all objects are in a namespace. Some resources such as nodes and PersistentVolumes are not in any namespace.
Kubernetes Objects
K8s objects are used to describe the intended state of the cluster. The two most common ways to create and update the cluster state are using the Kubernetes API or .yaml files.
They can describe which applications are running (and on which nodes), the resources available, policies regarding restarts, upgrades, and so on.
When a k8s object is created, the system will try to maintain the state described in the object. The desired state of a k8s object is called spec and the `status' describes the current state of the object.
Here's an example from the official docs of a manifest, which is the .yaml (or .json) file that describes a k8s object:
apiVersion: apps/v1 # Required: version os k8s API used to create the object
kind: Deployment # Required: kind of object to be created
metadata: # Required: data that helps uniquely identify the object
name: nginx-deployment
namespace: app-development # Optional: helps to separate objects based on their contexts
spec: # Required: the desired state of the object
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
The spec format will differ depending on the kind of object. The Kubernetes API reference can be used to check specific formats for each object.
Now, let's dive into some of the k8s objects.
Pod
Pods are the smallest units of computing that you can create and manage in Kubernetes.
A Pod contains one or more application containers (but most of the time, one pod has only one running container). In summary, a pod is a wrapper around one or more containers, that has configurations used by k8s. Although it is possible to create Pods directly, generally they are created from workload resources.
Deployment
A Deployment manages a set of Pods to run an application workload, usually one that doesn't maintain state.
It is possible to use Deployments to create ReplicaSet, manage and update Pod states, rollback to earlier revisions, and scale up or pause workloads.
ReplicaSet
A ReplicaSet's purpose is to maintain a stable set of replica Pods running at any given time. Usually, you define a Deployment and let that Deployment manage ReplicaSets automatically.
A ReplicaSet, often derived from a Deployment, has criteria regarding the number of Pods and what template should be used and, to meet the criteria, it creates or deletes Pods as needed.
Service
Expose an application running in your cluster behind a single outward-facing endpoint, even when the workload is split across multiple backends.
In Kubernetes, a Service is a method for exposing a network application running as one or more Pods in your cluster without requiring modifications to the application for service discovery. It abstracts the underlying Pods, which are ephemeral and dynamically managed by Deployments, ensuring that clients can interact with the application consistently. Each Pod gets its own IP address, but the set of Pods can change over time. Services provide a stable endpoint for these Pods, defining a logical set of endpoints and policies to make them accessible, thus decoupling the frontend clients from the backend Pods. This abstraction simplifies the interaction between different parts of the application, such as frontends and backends, by managing the dynamic nature of Pods.
Ingress
Make your HTTP (or HTTPS) network service available using a protocol-aware configuration mechanism, that understands web concepts like URIs, hostnames, paths, and more. The Ingress concept lets you map traffic to different backends based on rules you define via the Kubernetes API.
Kubernetes Ingress manages HTTP and HTTPS traffic to services within a cluster by defining routing rules. It enables external access to services with features like load balancing, SSL/TLS termination, and name-based virtual hosting. An Ingress controller is necessary to implement these rules, typically using a load balancer or configuring edge routers.
However, Ingress is limited to HTTP/HTTPS traffic, and other protocols need different service types, such as NodePort or LoadBalancer. While multiple Ingress controllers are available, they may have slight operational differences despite aiming to follow a standard specification.
Currently, Ingress is frozen, and the Gateway API is its successor.
Ingress Controller
For an Ingress resource to function, a cluster must have a running ingress controller, which is not started automatically like other controllers in Kubernetes. You need to manually select and deploy the appropriate ingress controller for your cluster from available options.
StatefulSet
A StatefulSet runs a group of Pods and maintains a sticky identity for each of those Pods. This is useful for managing applications that need persistent storage or a stable, unique network identity.
A StatefulSet is a Kubernetes workload API object that manages stateful applications by ensuring the unique and ordered deployment, scaling, and rescheduling of Pods. Unlike Deployments, StatefulSets assign each Pod a persistent identity, which is maintained across rescheduling, making Pods non-interchangeable. This feature is especially useful when persistent storage is needed for workloads, as Pods can be matched to their existing storage volumes even after failure. StatefulSets are ideal for applications requiring stable, unique network identifiers, persistent storage, ordered deployment, and automated rolling updates. Examples include databases like MySQL, and Cassandra, and distributed systems like Kafka, where stable identities and ordered operations are crucial.
ConfigMap
A ConfigMap is an API object used to store non-confidential data in key-value pairs. Pods can consume ConfigMaps as environment variables, command-line arguments, or configuration files in a volume.
A ConfigMap in Kubernetes separates environment-specific configuration from container images, making applications more portable. It is ideal for storing non-confidential configuration data, such as environment variables, but does not provide secrecy or encryption. For sensitive data, a Secret or third-party encryption tool should be used. ConfigMaps allows you to easily adjust settings for different environments, such as using localhost for development and a cloud service for production, without altering application code.
Secret
A Secret is an object that contains a small amount of sensitive data such as a password, a token, or a key. Such information might otherwise be put in a Pod specification or in a container image. Using a Secret means that you don't need to include confidential data in your application code.
Secrets in Kubernetes are designed to store confidential data separately from the Pods that use them, reducing the risk of exposure during Pod creation, viewing, and editing. Kubernetes and applications can take extra precautions, such as preventing sensitive data from being written to nonvolatile storage. While similar to ConfigMaps, Secrets are specifically intended for handling sensitive information.
Volumes
Managing storage in Kubernetes is separate from managing compute instances, and the PersistentVolume (PV) subsystem provides an abstraction to handle storage provisioning and consumption. A PersistentVolume (PV) is a cluster resource, either manually or dynamically provisioned, that can be used by Pods but has an independent lifecycle. Users request storage through PersistentVolumeClaims (PVCs), which are similar to Pods but for storage resources, allowing users to specify size and access modes. To offer diverse storage options without exposing implementation details, cluster administrators can use StorageClasses to define different types of PersistentVolumes, such as for varying performance needs.
Job & CronJob
Jobs represent one-off tasks that run to completion and then stop.
A Kubernetes Job creates one or more Pods and continues retrying them until a specified number is successfully complete. The Job tracks these completions and terminates when the required number is reached. Deleting a Job cleans up its Pods, and suspending it deletes active Pods until resumed. Jobs can be used to run a single Pod to completion or multiple Pods in parallel. For scheduled tasks, a CronJob can be used to run Jobs at specified intervals.
A CronJob starts one-time Jobs on a repeating schedule.
A CronJob in Kubernetes is used for scheduling regular tasks like backups or report generation, similar to a crontab entry in Unix. It runs Jobs periodically based on a Cron format schedule. However, CronJobs have limitations, such as potentially creating multiple concurrent Jobs under certain conditions.
There are other types of k8s resources, and is it possible to create custom resources but overall, the resources covered here are enough to deploy the majority of applications.
Kubernetes Alternatives
While Kubernetes dominates the container orchestration landscape, it's not the only option available, and there are several other platforms worth considering based on specific needs and use cases.
Apache Mesos
Mesos was launched before Kubernetes and is often used for both containerized and non-containerized workloads. Unlike Kubernetes, which is primarily focused on container orchestration, Mesos provides a more generalized framework that can handle other distributed systems, such as Hadoop and Spark. It shines in environments where the orchestration of diverse types of workloads (beyond just containers) is necessary. However, Kubernetes has overshadowed Mesos due to its dedicated focus on containers and larger community support.
Docker Swarm
Docker Swarm is another alternative to Kubernetes, particularly suited for smaller-scale deployments or teams seeking simplicity. Swarm integrates tightly with Docker and offers a more straightforward setup and learning curve compared to Kubernetes. It's easier to use but lacks the extensive scalability and features Kubernetes provides, such as custom resource definitions and advanced network policies. For users prioritizing ease of use over complexity, Docker Swarm can be a good fit.
Nomad by HashiCorp
Nomad offers a simpler, lightweight alternative to Kubernetes. While Kubernetes excels in managing complex, multi-service applications, Nomad is designed to be easy to install and run. It supports a broad range of workloads, including containers, virtual machines, and standalone applications, which makes it flexible. For those who find Kubernetes' learning curve too steep or need a lightweight orchestration tool, Nomad can be an excellent choice.
Each of these platforms comes with its strengths and trade-offs, making them viable alternatives to Kubernetes depending on the specific needs of your organization or project. While Kubernetes has gained massive adoption due to its feature richness and ecosystem, tools like Mesos, Docker Swarm, and Nomad still hold relevance for simpler, more specialized, or resource-constrained environments.
Conclusion
After more than a year of working with Kubernetes, I've learned many concepts by doing several changes in the cluster. However, to fully master the Kubernetes I have to take this step back. After writing this very first post I can say it has already made a lot of "clicks" in mind about how Kubernetes really works. In the next post, I will set up a simple cluster using minikube to reinforce some of the concepts learned in this post.